Summary
By sharing more code between individual instances of call commands, translated program size can be reduced 7-12%.
Background
The ASM code required for the VM call and return commands is long, around 50 instructions for each command, so it is not practical to generate the entire sequence for every instance of these commands.
There are other posts on the forum that show how to use assembly language subroutines to implement the translations for the call, gt, lt and eq commands.
The return command does not require a subroutine. Because it is identical code for all instances, all the remaining return commands can simple jump to the first return command which contains the ASM code.
Basic optimization for the VM call command
The subroutine based call implementation requires passing 3 parameters to the subroutine: the target function address, the number of parameters and the return address. Two of the parameters can be passed in temporary registers and the third parameter can be passed in the D register.
// call Fred 3
@Fred // Target function address
D=A
@R15
M=D
@3 // Number of arguments
D=A
@R14
M=D
@$RET$123 // Return address
D=A
@$CALL$FUNCTION
0;JMP
($RET$123)
This requires 12 instructions per call plus a fixed cost for the $CALL$FUNCTION subroutine.
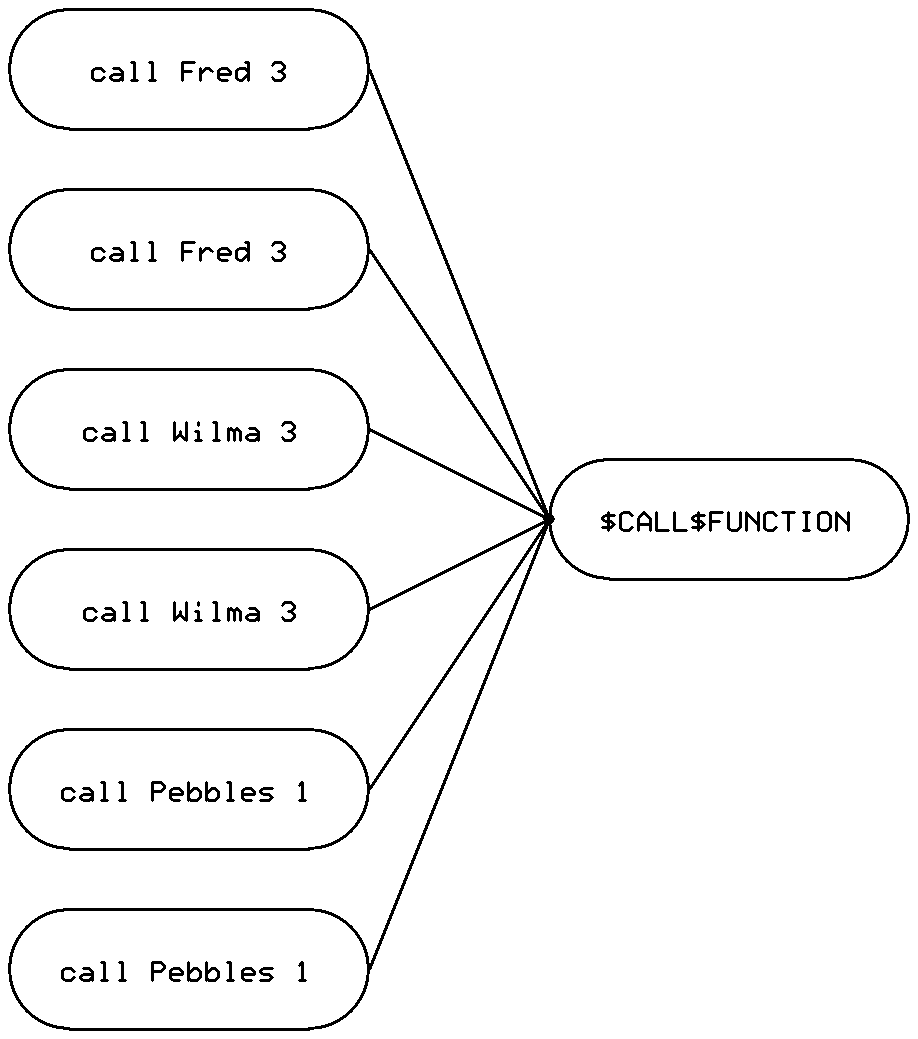 |
| Figure 1: All call statements set all parameters |
Additional optimization for the VM call command
It is possible to further reduce the amount of ASM code that is written for
call commands by identifying more common code sequences.
Except for the return address value, the above code is identical for all instances of call Fred() with 3 arguments.
Rearranging the code slightly, all the calls to 3-argument Fred() can share a single copy of the code.
// call Fred 3
@$RET$123 // Return address
D=A
// Common code for 'call Fred 3'
// On entry, D = return address
($CALL$Fred$3)
@R15
M=D
@Fred // Target function address
D=A
@R14
M=D
@3 // Number of arguments
D=A
@$CALL$FUNCTION
0;JMP
($RET$123)
(
Note that R15 and D register have swapped which argument they hold. $CALL$FUNCTION will need to be modified appropriately.)
All subsequent calls to 3-argument Fred() only need to set the return address in the D register and jump into the first call.
// call Fred 3
@$RET$456 // Return address
D=A
// Jump to code for 'call Fred 3'
@$CALL$Fred$3
0;JMP
($RET$456)
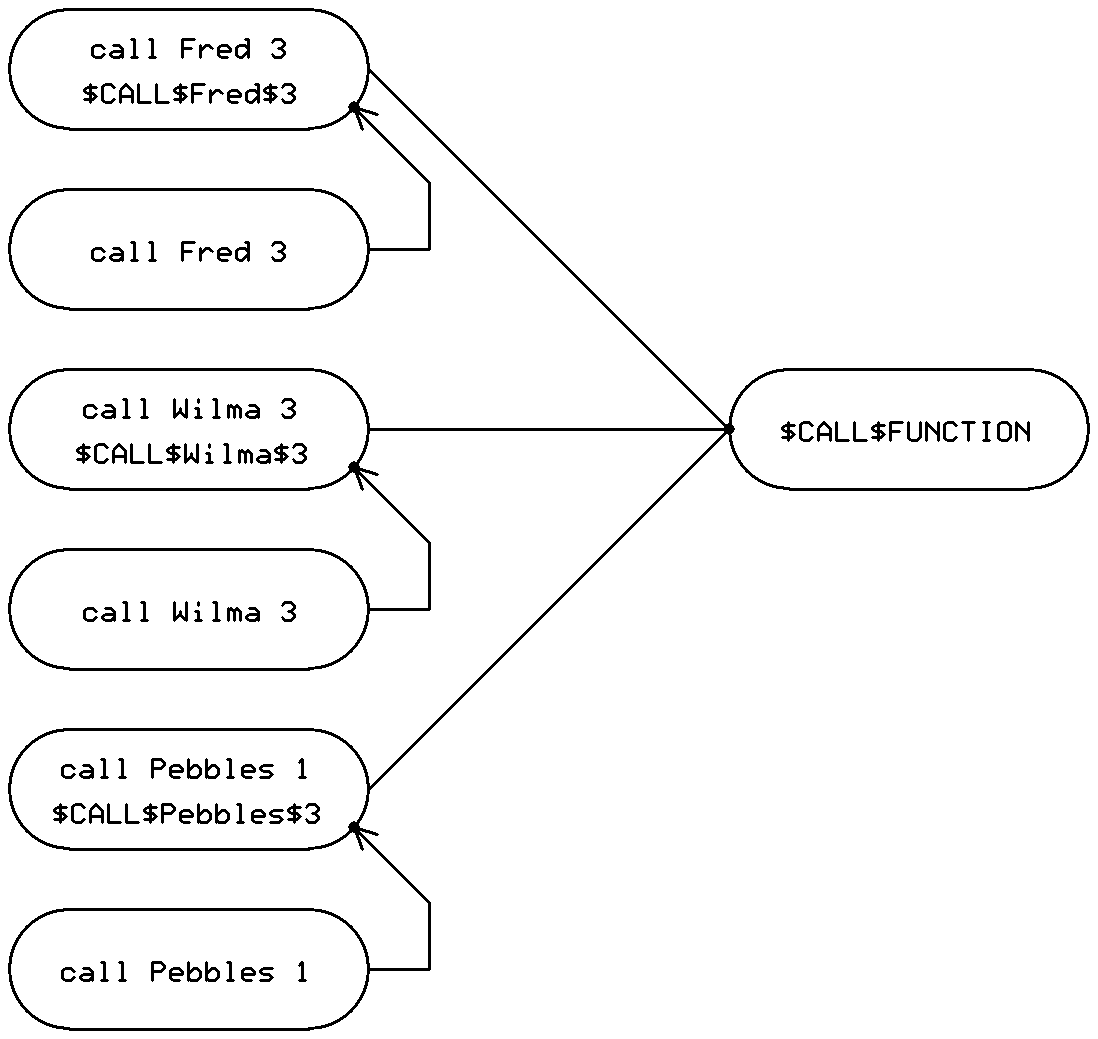 |
Figure 2: call statements to same function
share target address and nArgs code. |
How effective is this optimization?
Pong calls 66 unique functions with 274 total calls. For the simple version without this optimization, this results in 274 * 12 = 3288 instructions for all the calls (not including $CALL$FUNCTION).
On average, each function is called 4.1515 times. Each additional call to a function saves 8 instructions so the total savings is 66 * 3.1515 * 8 = 1664 instructions; a bit over 50%. The overall size of Pong is reduced by about 7%.
The jumps to the repeated call code require two instructions. For Pong, 274 - 66 = 208 calls will get the jumps. This averages out to about 1.5 instructions per call.
This is an insignificant execution overhead compared to the 50+ instructions required to store the target, nArgs and return address parameters and run the $CALL$FUNCTION code.
A bit more complex: adding a third level
Notice in the optimized code, a label could be placed near the end of of the "call function N" common code blocks. This would allow calls to all functions that have that same number of arguments to share the code that sets the
nArgs parameter.
// call Fred 3
@$RET$123 // Return address
D=A
// Common code for 'call Fred 3'
// On entry, D = return address
($CALL$Fred$3)
@R15
M=D
@Fred // Target function address
D=A
// Common code for 'call <fn> 3'
// On entry, R15 = return address, D = target address
($CALL$$3)
@R14
M=D
@3 // Number of arguments
D=A
@$CALL$FUNCTION
0;JMP
($RET$123)
This saves 4 instructions in the $CALL$Some.function$N code for every additional function that shares nArgs = N.
// call Wilma 3
@$RET$456 // Return address
D=A
// Common code for 'call Wilma 3'
// On entry, D = return address
($CALL$Wilma$3)
@R15
M=D
@R15
M=D
@Wilma // Target function address
D=A
// Jump to code for 'call <fn> 3'
@$CALL$$3
0;JMP
($RET$456)
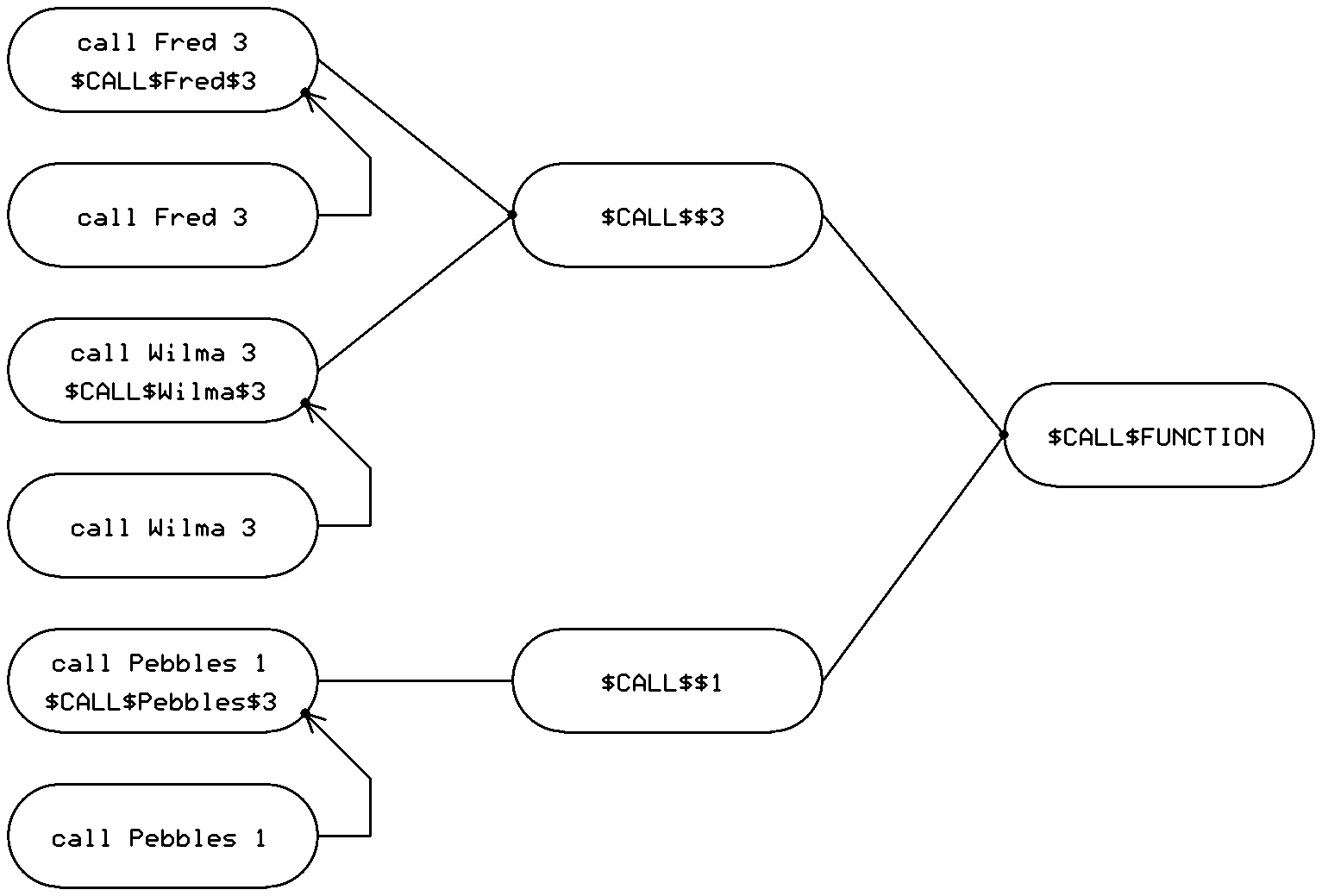 |
Figure 3: call statements to same function share target
address code. All calls with same nArgs share nArgs code. |
Pong has 66 functions and 6 unique nArgs values. On average, there are 11 functions per nArgs value, so this saves 10 * 40 * 6 = 240 instructions. Adding the third level will save an additional 1% in Pong's overall code size.
This third level of optimization adds 2 instructions to all but 6 calls in Pong. Adding this to the 1.5 instructions for the second level jumps gives 3.5 instructions per call overhead. My worst case call code is 56 instructions, so this is about 6.3%.
Unscientific profiling of my Reflect game shows that about 15% of the time is spent in call code. This means that the additional jumps for the 3-level call optimization will cost about 1% in execution speed. This seems like a reasonable tradeoff, so I include this third level in my code generator.
Real world results
This table shows the generated code size using single-level $CALL$FUNCTION and the 2- and 3-level common code described in this article.
Reflect is my project 9 game. It has many constant strings so there are lots of String.appendChar() calls. (The Jack compiler creates constant strings on the fly.)
Trig is my floating point trigonometry demonstrator. It has lots of calls to floating point math functions which have lots of calls to multi-precision integer math functions. (Trig is still too big to fit in ROM without further optimization. Turning on all my optimizations, Trig comes out 26016 speed optimized and 22037 size optimized.)
| |
Pong | |
Reflect | |
Trig |
| |
| Functions | |
66 | | |
94 | | |
111 |
| Calls | |
274 | 4.2 : 1 | |
638 | 6.8 : 1 | |
772 | 7.0 : 1 |
| Unique nArgs | |
6 | | |
6 | | |
6 |
| |
| Code size |
| 1-level opt. | |
22202 | | |
34609 | | |
39803 |
| 2-level opt. | |
20593 | -7.2% | |
30370 | -12.2% | |
34751 | -12.7% |
| 3-level opt. | |
20406 | -8.1% | |
30073 | -13.1% | |
34394 | -13.6% |
Not surprisingly, the saving is greater for the programs with higher calls-to-functions ratio.

