Henoktes722 wrote
Yeah It seems complex. That is why I was asking you to show me some vm to assm mappings, so that I will do my vm translator following that mapping.
Actually, it's not as convoluted as I was first thinking. I've been working with a machine that has four registers and it's amazing how much more efficient you can make code when that's the case -- even just a single additional register makes a huge difference.
For your pop pointer command your basic approach is this:
Store the target address at R13
Pop the top of the stack into D
Store D into the target address
You are using 15 instructions to do this. There is some low-hanging fruit that can trim a couple of instructions, but to make serious headway you need to explore various options. The first way that we come up with is seldom optimal -- but it gives us a working solution to then tease improvements out of or to better identify even radically different alternatives by recognizing what parts of our current approach are the apparent bottlenecks.
There are several alternatives that could be considered. For instance, we could store the value to be written into a temporary register, adjust the stack pointer, get the target address into A, and then write the value from the temporary register into the target address. But since we need to do arithmetic on the pointer to get the address, we can't leave something in the D register while we do it. That's where having just a single additional register would help enormously -- and hence we've identified a major bottleneck: the need to do pointer arithmetic. So the next question is whether we can figure out a way to simply avoid doing the pointer arithmetic.
We should always consider what information the translator has at translation time and how it can exploit it.
Your code is having the Hack add the base of the pointer segment (which is always 3) to the index (which, while it varies from command to command, is known by the translator whenever it is translating a specific command). What if you have the translator do the arithmetic?
Also, remember that one thing the Hack can do that most real processors can't is write to multiple destinations with the same command. As a result, you can pop the top of the stack into the D register and decrement the stack pointer at the same time using a total of just three instructions.
If you leverage these two things you can perform a pop to the pointer segment using a total of just five assembly language instructions without using any of the temporary registers.
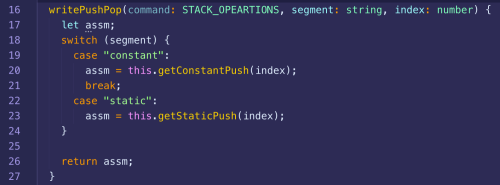
Turning the attention to the static segment stuff, you look like you are doing that right.
Do you see how, regardless of which order you translate bob.vm and sue.vm, you will get the same behavior? Sure, bob.3 and sue.3 will map to different memory locations depending on what order the files are translated in, but that's fine. All that we need to ensure is that whatever memory location bob.3 maps to that no other variable can map to that same address and that any value written to bob.3 from anywhere at anytime in the program will survive and be accessible by any later access to bob.3 from anywhere at anytime in the program.