Good news everyone! I am finally able to generate actual .asm file runnable on vanilla CPU emulator. Time to bore you with some analysis.
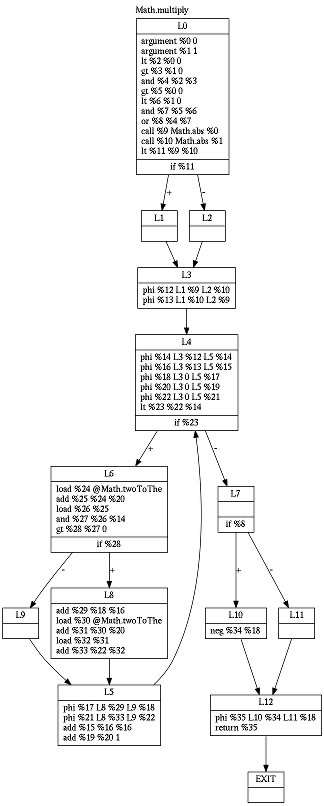
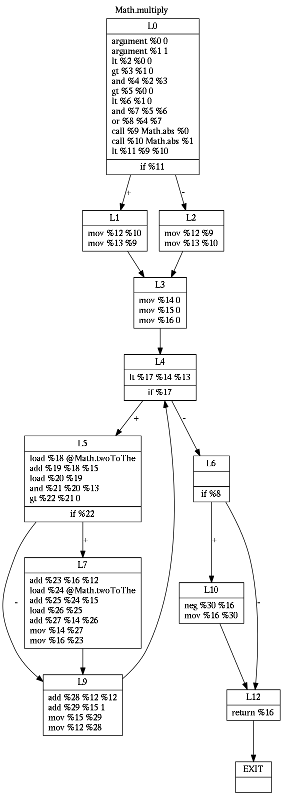
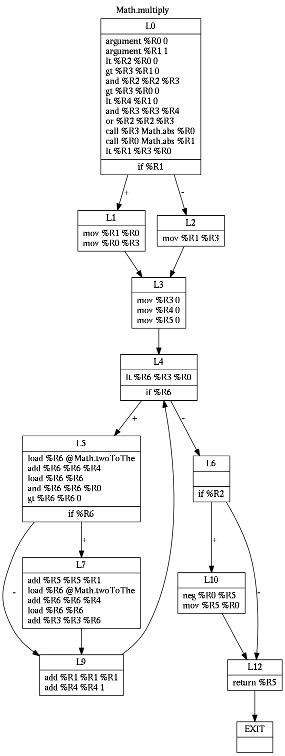
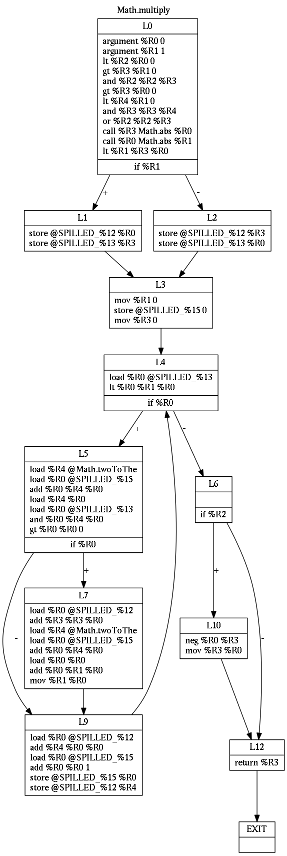
To benchmark generated code, I translated Pong game using my (quite capable) jack2vm2asm translator and (newly developed) jack2ssa2asm translator:
As for the runtime speed, both files run at surprisingly similar pace, despite their difference in size. SSA version is larger by about 20%. Similar runtime performance is thus a good sign for me, as I have not yet employed any serious oprimizations in jack2ssa2asm translator.
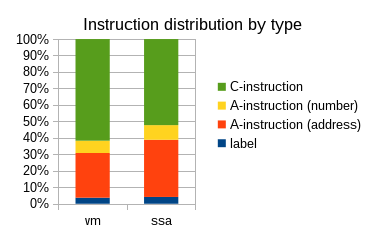
The graph shows differences in instruction distribution. You can see that current SSA version uses more labels than VM version. The reason is an optimization in my VM-based translator which is sometimes able to coalesce comparison with following branching.
Another difference lies in ratio between C-instructions and A-instructions. "Optimal" code is expected to have ratio around 1:1, alternating between loading the data and performing computations on data. I am thus quite satisfied with SSA-based translator so far.
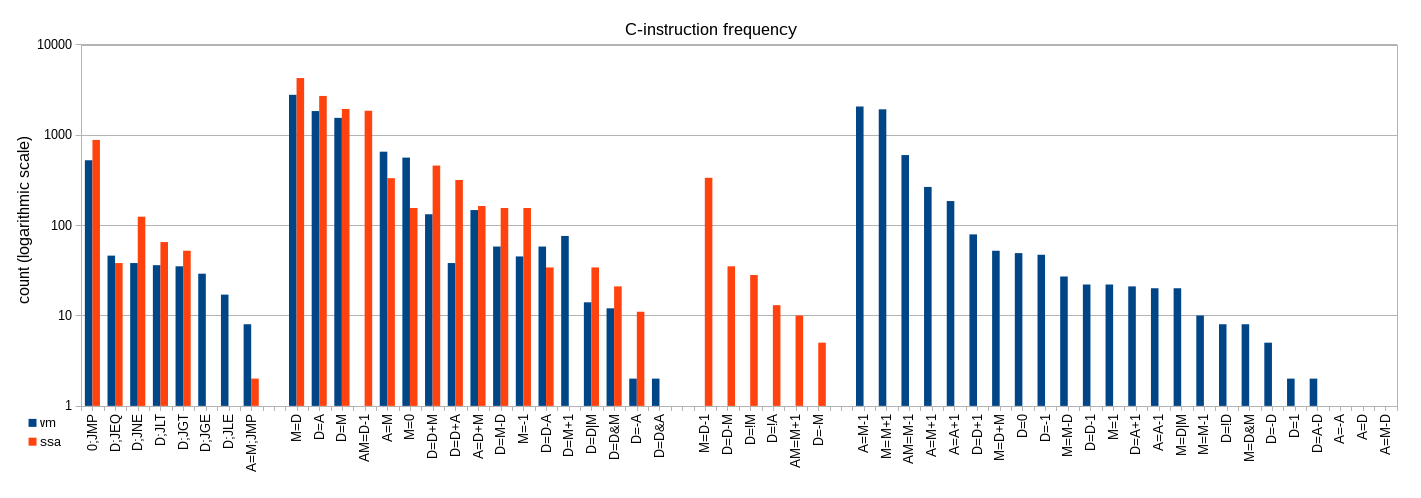
Next graph shows frequencies of C-instructions in logarithmic scale. I divided the graph into 4 parts.
First part shows branching instructions. Unconditional jumps count is directly proportional to count of labels, as discussed before. VM-based translator is sometimes able to coalesce negation with comparison, therefore it generates jumps not generated by SSA-based translator. Difference in relative jump is due to my VM-based compiler generating different versions of "call helper" for different arguments count.
Second part of the graph shows non-jump instructions generated by both translators, last two parts show instructions generated by solely SSA or VM based translator, respectively. Striking feature is that SSA-based translator does not utilize instructions containing constant zero and one as much as VM-based translator does. Zeros and ones are instead loaded through A-instruction. This is intentional. For my VM-based translator, I included ad-hoc generation of special code for different constants. In my new SSA-based translator I decided to generate straightforward code and have a second pass run on this code, which should propagate simple constants. This second pass is not implemented yet.
Instructions with 100 and more instances are likely participating on transfering data between subroutines on stack. I am not going to describe my calling convention yet, as I would like to change it later. I intend to pass some arguments and the return value in dedicated registers.
To sum up, I am quite happy with results so far. Runtime speed is comparable and I already see lots of improvements to implement. Plus, it is great to see the code finally running on "real" hardware -- CPU emulator.