Hi,
I want to share a code generation technique that allows to significantly reduce the code size of Hack programs. Having said that, there is non-surprisingly a tradeoff: the speed will also decrease (init time until Pong actually starts may take up to 18 seconds...).
I have achieved the following code sizes (for all versions the 2 Sys.wait calls in PongGame have been removed - same as in the official Pong.asm from project 06):
Pong (official OS and compiler): 7288
Pong_refOS.hackPong (official OS and own compiler/optimizer): 6568
Pong_refOSopt.hackPong (own OS and own compiler/optimizer): 5596
Pong_akOS.hack (actually much faster than the original because my Screen.drawRectangle is more efficient)
The code density for the above is between 1.85 ad 2.27 ASM instructions per VM instruction!
For Pong itself this is more a proof-of-concept since you can easily reduce its size below 32k with various ideas posted in this forum (i.e. dead code removal, global return function, ...).
However, for more complex programs this will not be sufficient. I have implemented nand2tetris on a FPGA and wanted to have something more impressive than Pong running on it. For example the raycaster presented
here(Current generated code size 24047, at first this seemed impossible since the program plus official OS has 28601 VM instructions (excluding labels) after dead code removal. But the code is full of constant array accesses (pre-computed trigonometry), which my optimizer reduced significantly, ending up with only 10855 VM instructions. Code density of 2.22 ASM/VM. I will publish it soon.)
The slower speed is not really an issue on the FPGA since it is running much faster than the official CPU emulator (which runs with JDK8 at about 1MHz).
How do I achieve this:
1.
Threaded Code2. Code deduplication
3. Improved VM code generation (for the optimized versions)
4. Lots of small nasty hacks exceeding the scope of this post...
1. Threaded code
-------------------
This is the most important feature. The main idea is that VM commands are not generated inline but instead as internal subroutines:
(PUSH_LOCAL_5)
// save return address
...
// push
@5
D=A
...
//internal return
...
The trick here is how can we keep the call to the internal subroutine small. It is typically assumed that an internal call requires 4 ASM instructions:
@retaddr1
D=A
@PUSH_LOCAL_5
0;JMP
(retaddr1)
If you cascade many of such calls you will notice, that all the return addresses are just 4 words apart. In other words D is increased by 4 for every internal call. Afterwards each of the internal subroutines will save D into some internal register (let's say R15). That sounds quite inefficient, doesn't it? What if we permanently use R15 as some kind of internal program counter? Instead of passing a return address to the internal routine, the program always "knows" where it is and where to continue.
This is how it looks like:
(PUSH_LOCAL_5)
// no need to save a return address
// directly start with the push
@5
D=A
...
// PC+=2
// increase R15 by 2 and jump to that address (which is the next call to an internal VM command)
...
// call to push local 5 no longer requires to pass a return address
@PUSH_LOCAL_5
0;JMP
// and so on...
@PUSH_CONSTANT_7
0;JMP
...
So we have managed to reduce each call to a VM command to only 2 words! This is the main principle, though you can still improve a lot in order to reduce the overhead of the internal subroutines. Specifically I am using parametrized subroutines. I don't want to go too much into detail here, but you may figure out when analyzing the code in the CPU emulator.
The code for increasing R15 by 2 can be done with 4 ASM instructions at the end of each internal subroutine. I have opted for another solution, putting the code into another subroutine, leaving us with only 2 instructions to call that routine. With a nasty hack, the speed overhead for R15+=2 is only 2+3 cycles this way. So I am saving 2 instructions per occurrence and losing only 1 cycle on speed. That's why I thought it is worth it. You may want to figure out how the PC+2 routine works in the CPU emulator...
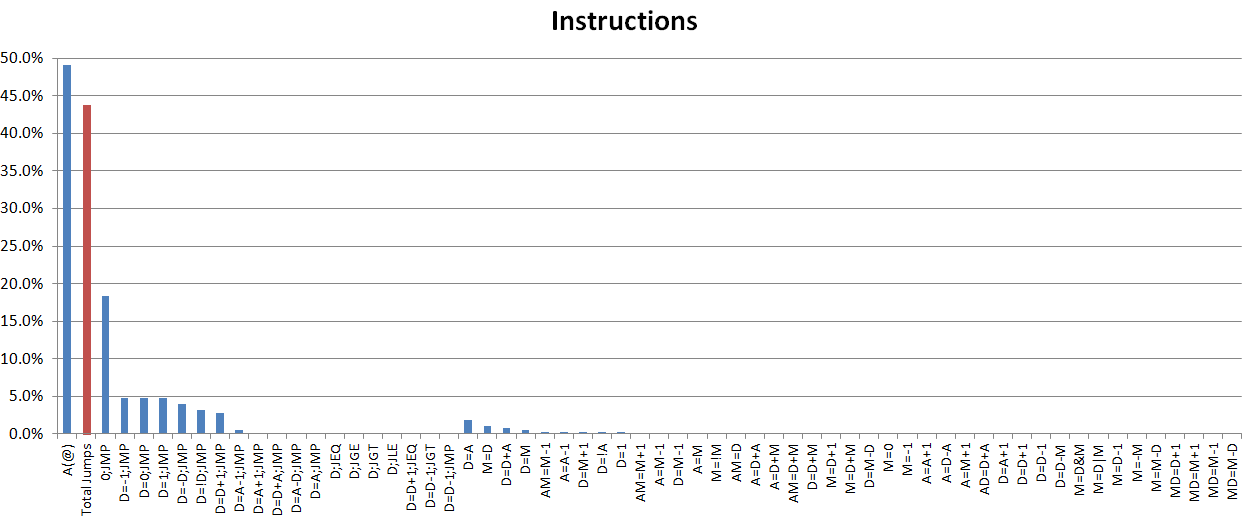
This approach will lead to a rather unusual distribution of instructions with nearly 50% A-Commands and 41% jumps(!):
The code is basically an endless cascade of jumps. You can think of threaded code as a Hack-based interpreter or emulator for VM code.
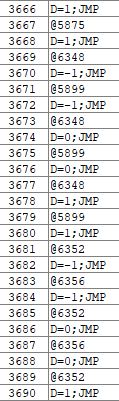
2. Code deduplication
------------------------
The entropy of Hack code is generally quite low, with lots of instruction sequences repeating. This is true on both VM level and ASM level. The official OS contributes even more to this due to the charset bitmaps (my own OS uses a compressed charset requiring only 285 constants instead of 96*12=1152...).
My code generator is looking for such repeating sequences and putting them again in internal subroutines. You may look at some of the VM files and will for sure recognize typical sequences yourself. Depending on the sequence this will typically require an internal return address to be stored (I use R14).
3. Improved VM code:
-------------------------
This is more a topic for the compiler project. But just to outline some of the main things:
- improved array handling
- avoid the temp 0 storage (a[expr1]=expr2 -> if expr1 is calculated AFTER expr2 there is no need to use temp)
- prevent unnecessary update of pointer 1 (accessing the same array twice)
- using that <const> instead of setting pointer 1 with adding a constant and then using that 0
- improved conditional jumps/flow
- handling of void functions (already suggested by some here, but I believe they missed the point that just removing the pop temp 0 will lead to a corrupted stack over time)
- remove push constant 0 (this can generally be done safely since SP is restored based on ARG by RETURN routine)
- separate global return routine for void functions, avoiding to leave a return value on the stack, and remove the pop temp 0 for DO statements (be careful, it is allowed to call a non-void function with do, just ignoring the return value...)
Final comment:
-----------------
As mentioned this technique only makes sense if the program doesn't fit into the 32k. Otherwise a normal inline code generation approach will do better. Theoretically a mix of both approaches is possible to achieve the maximum speed while remaining below 32k (or for example opt for in-lining the increase of R15 instead of a subroutine as described above)
Is this the best we can do? Definitely not. There are still a few things that I haven't implemented. A simple thing to increase speed while maintaining the size is to change the convention for push and pop as suggested in another post (SP pointing to last stack element instead of pointing behind it). While this reduces the size of inline code, the threaded code size is more or less not impacted by it since the stack access is in subroutines.
The handling of the code deduplication is also not optimal and can be further improved, both to reduce size (however not much...) and improve speed.
The approach in my code is generally stack inefficient and accesses the stack with every single VM command. This approach could be changed into using the D register (which is typically what you do for speed optimized inline code). Doing this with threaded code is possible, but it will create much more overhead (prevents parametrization). Without having tested it, I would guess that the code size would be larger, but a bit faster.
I have also experimented with some compressed VM code interpreter, encoding 3 of the most common VM instructions into one word (5 bits each). While this is possible and I made a PoC with an interpreter kernel requiring 76 ASM instructions, it will further and significantly reduce speed and I don't think the additional size reduction would justify.
One thing that I have implemented, but which doesn't work with the official CPU emulator due to a bug discussed
here is a feature that I call setOnJump. It makes use of the fact that a jump often goes to a label which is followed by @SP (or @LCL). Setting A to zero (which is what @SP does) can be achieved while jumping:
A=0;JMP
While this works in the Hardware Simulator and on real Hardware, the official CPU emulator wrongly updates A before executing the jump, jumping to address 0 (unless you install my patch as posted in the
thread). So I have omitted this in the above versions. It will speed up the code by about 4%.
Another idea is to replace some Jack-based OS routines with ASM code. This is especially useful for Math.multiply and divide.
I hope the general concept is clear. Feel free to ask if I haven't made things clear enough :-)