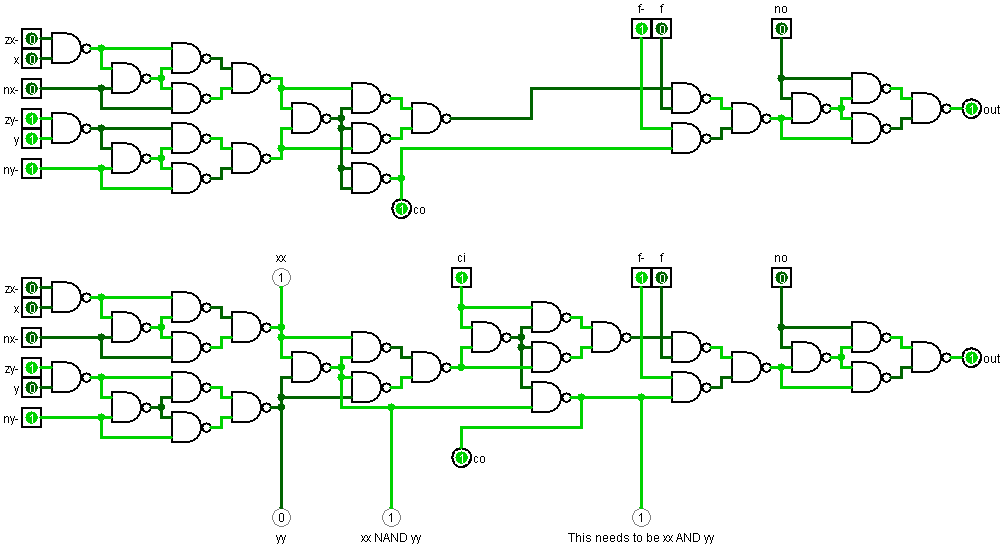
What comes to mind is this:
What is the usefulness of this exercise. As Mark pointed out to me earlier on this forum this ALU wouldn't hold up in the real world due to race and hazard glitches.
Simplifying chipsThe most important lesson:
By rewiring the ALU to its minimal Nand implementation you will rewire your brain. You start recognizing the importance of analyzing of what is asked and what is given. What information can I compute before even processing i/O values. Most astonishing was that X and Y value could act as selection bit for the Mux handling nx,ny and zx,zy.
Seeing the patterns:
In this table out doesn't reveal much
nx zx x | out
0 0 0 | 0
0 0 1 | 1
0 1 0 | 0
0 1 1 | 0
1 0 0 | 1
1 0 1 | 0
1 1 0 | 1
1 1 1 | 1
but if you re-arrange the table
nx zx x | out
0 0 0 | 0
0 1 0 | 0
1 0 0 | 1
1 1 0 | 1
0 0 1 | 1
0 1 1 | 0
1 0 1 | 0
1 1 1 | 1
you see when x=0 out=nx
when x=1 out=Not(nx Xor zx)
So before going to the next chapters keep in mind, stay open minded!
Koen